Serverless API Data Ingestion in Google BigQuery: Part 1 (Introduction)
Ingesting API Data in Google BigQuery the Serverless way!
API To Google BigQuery
In the era of cloud computing, Serverless has become a buzzword that we keep hearing about, And eventually, we get convinced that serverless is the way to go for companies of all sizes because of various advantages. The basic advantages of the Serverless approach are :
No Server Management
Scalability
Pay as you go
In this article, we will also explore how we can use the Serverless approach to build our data Ingestion pipeline in Google Cloud.
Serverless Offerings In GCP
GCP offers plenty of Serverless Services in various areas such as mentioned below.
Computing: Cloud Run, Cloud Function, App Engine
Data warehouse: Google BigQuery
Object Storage: Google Cloud Storage
Workflow management: Cloud Workflow
Scheduler: Cloud Scheduler
Technically, the combination of the above tools is enough to build API data ingestion in GCP.
We can build Two patterns to ingest API data in Google BigQuery
Business Requirement
Let's consider you have a business requirement that you want to ingest/scrape data from various online resources and get the top headlines for every day. These headlines will be ingested to Google BigQuery and Every 1 day a scheduled query will be executed on BigQuery to calculate which media outlet published most headlines for a given day.
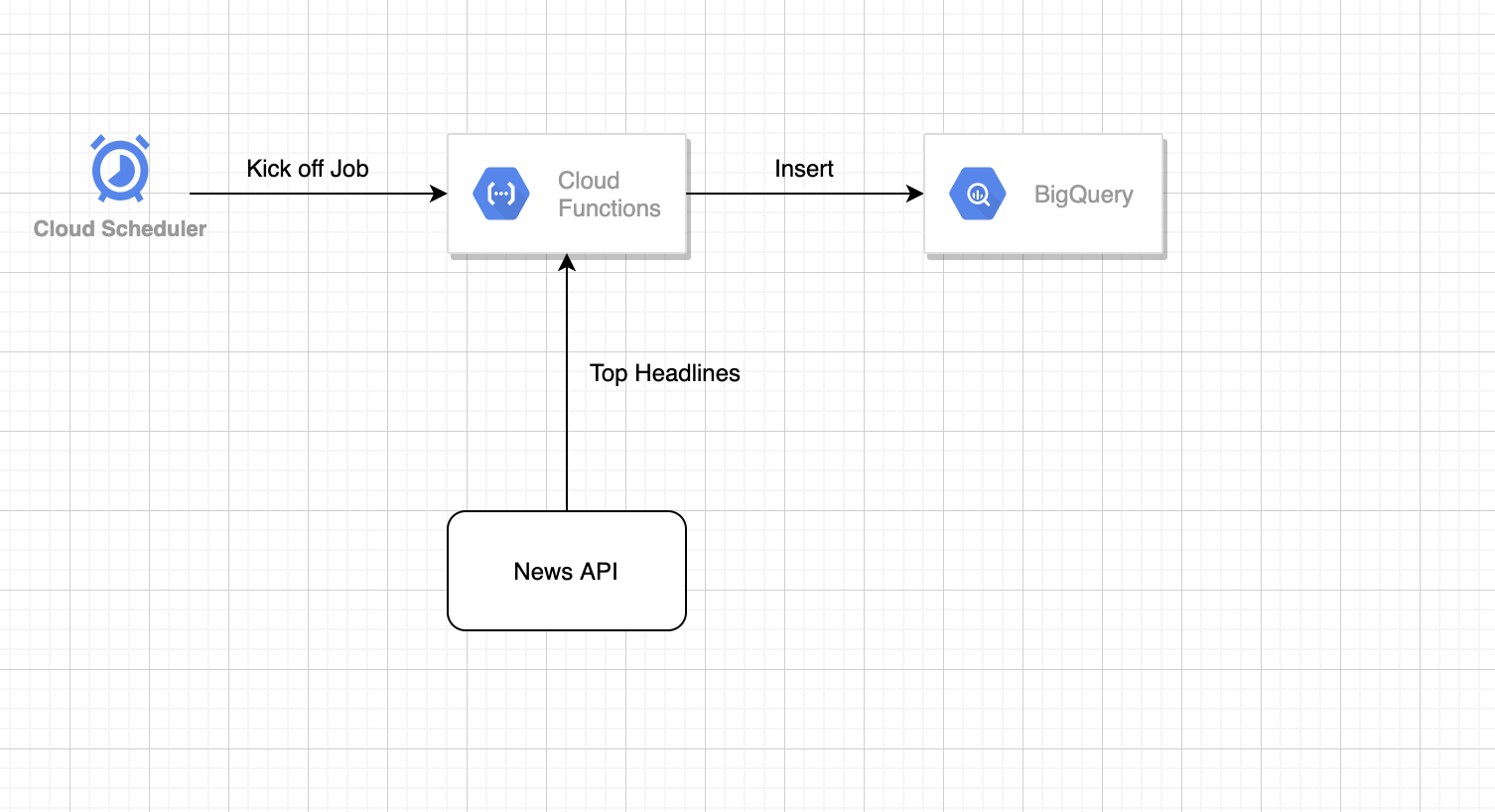
Pattern 1
Technical Design Now we can build this data ingestion pipeline in many ways. But if you really decided to go serverless below data pipeline might be a good approach.
Cloud function would be a good solution to write an API request and response handling code and we can also use Google BigQuery Streaming Insert API to write each news headline into BigQuery.
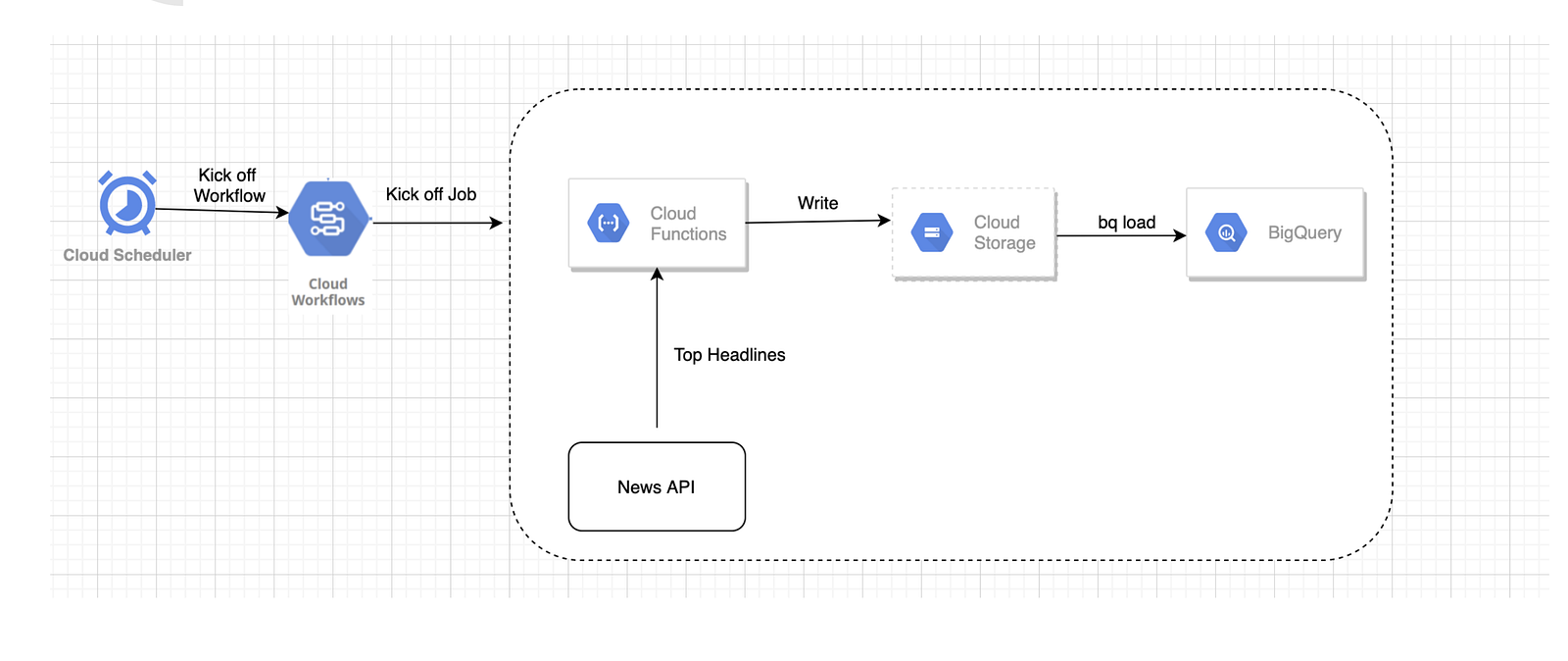
Pattern 2
Technical Design In this approach, we are basically breaking down the ingestion and insert task as separate steps. API request and response handling code will be written in Cloud function and all the news headlines record can be written into the GCS file instead of writing to BigQuery via Insert API. We would use the BigQuery Batch load command to load all the data from the GCS file into BigQuery.
We will orchestrate data ingestion and data load steps using cloud workflow which is another serverless offering in GCP.
Note: Streaming Insert to BigQuery mentioned in pattern 1 would cost an additional charge, while batch load data to BigQuery is completely free.
Part 2 of this blog where I share about code and configurations for the above-mentioned pattern.
This is the title of the webpage! Hi guys, Today we gonna talk about Kafka Broker Properties. More Specifically, advertised.listeners property. If you have seen the server.properties file in Kafka there are two properties with listener settings. #listeners=PLAINTEXT://:9092 #advertised.listeners=PLAINTEXT://your.host.name:9092 why the hell we need two listeners for our broker? usually, Kafka brokers talk to each other and register themselves in zookeeper using listeners property. So for all internal cluster communication happens over what you set in listeners property. But if you have a complex network, for example, consider if your cluster is on the cloud which has an internal network and also external IP on which rest of the work can connect to your cluster, in that case, you have to set advertised.listeners property with {EXTERNAL_IP}://{EXTERNAL_PORT}. For Example, If Internal IP is 10.168.4.9 and port is 9092 and External IP is...
This is the title of the webpage! Cloud Computing Weekly Newsletter is a weekly digest of all the major development and updates that happened in major cloud providers like GCP, AWS, Azure. Photo by Alex Machado on Unsplash
Comments
Post a Comment