This blog covers basic knowledge needed to get started ML journey on GCP. It provides foundational knowledge which will help readers to gain some level of confidence understanding ML ecosystem on GCP from where they can master each component.


Introduction to Machine Learning
- Machine Learning is a way to use some set of algorithms to derive predictive analytics from data. It is different than Business Intelligence and Data Analytics in a sense that In BI and Data analytics Businesses make decision based on historical data, but In case of Machine Learning , Businesses predict the future based on the historical data. Example, It’s a difference between what happened to the business vs what will happen to the business.Its like making BI much smarter and scalable so that it can predict future rather than just showing the state of the business.
- ML is based on Standard algorithms which are used to create use case specific model based on the data . For example we can build the model to predict delivery time of the food, or we can build the model to predict the Delinquency rate in Finance business , but to build these model algorithm might be similar but the training would be different.Model training requires tones of examples (data).
- Basically you train your standard algorithm with your Input data. So algorithms are always same but trained models are different based on use cases. Your trained model will be as good as your data.
ML, AI , Deep learning ? What is the difference?

AI is a discipline , Machine Learning is tool set to achieve AI. DL is type of ML when data is unstructured like image, speech , video etc.
Barrier to Entry Has Fallen
AI & ML was daunting and with high barrier to entry until cloud become more robust and natural AI platform. Entry barrier to AI & ML has fallen significantly due to
- Increasing availability in data (big data).
- Increase in sophistication in algorithm.
- And availability of hardware and software due to cloud computing.
GCP Machine Learning Spectrum

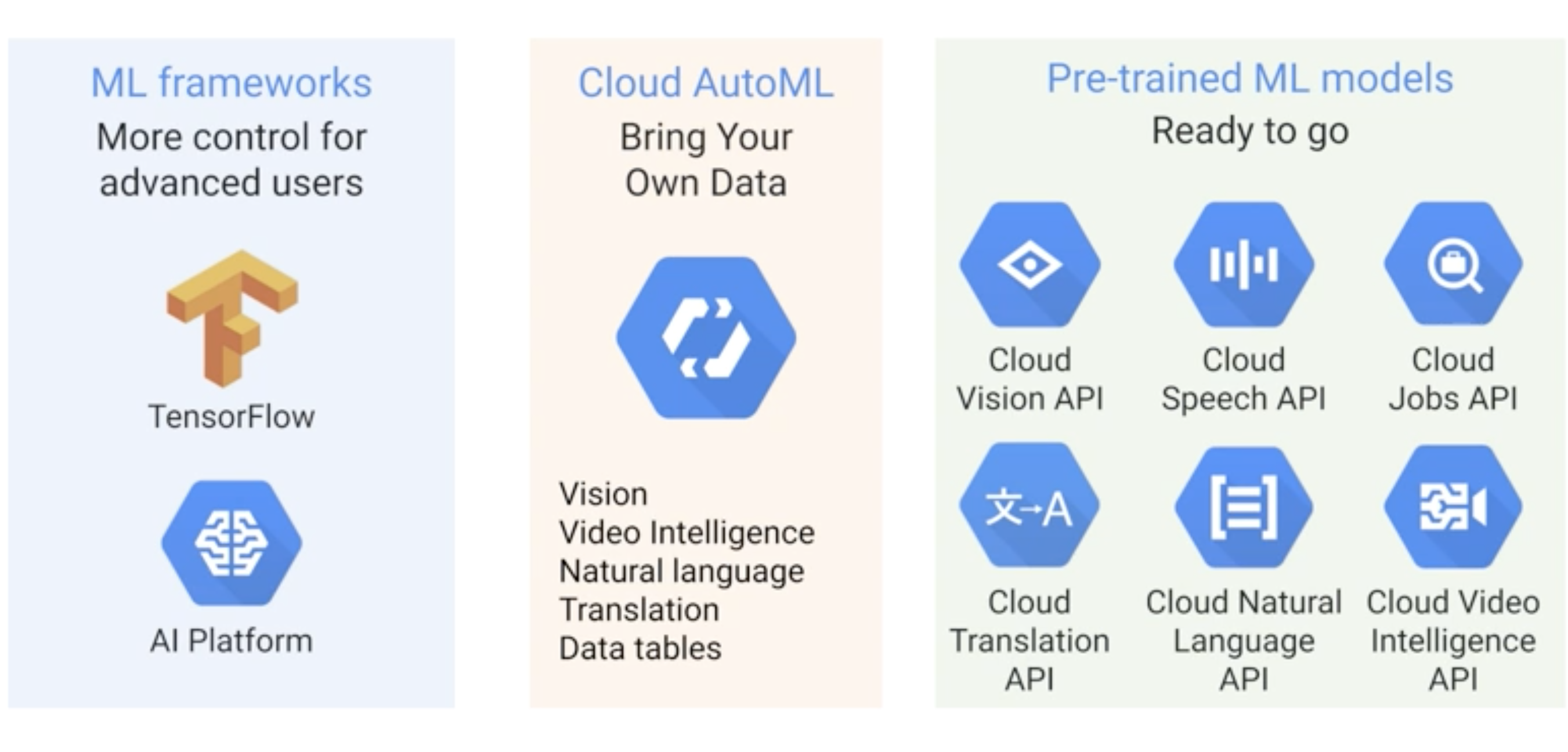
- For Data scientist and ML experts , TensorFlow on AI platform is more natural choice since they will build their own custom ML models.
- But for the users who are not experts will potentially use Cloud AutoML or Pre-trained ready to go model.
- In case of AutoML we can trained our custom model with Google taking care of much of the operational tasks.
- Pre-trained models are the one which are already trained with tones of data and ready to be used by users to predict on their test data.
Prebuilt ML Models (No ML Expertise Needed)
- As discuss earlier , GCP has lot of Prebuilt models that are ready to use to solve common ML task . Such as image classification, Sentiment analysis.
- Most of the businesses are having many unstructured data sources such as e-mail, logs, web pages, ppt, documents, chat, comments etc.( 90% or more as per various studies)
- Now to process these unstructured data in the form of text, we should use Cloud Natural Language API.
- Similarly For common ML problems in the form of speech, video, vision we should use respective Prebuilt models.
Building Custom ML Models (ML Expertise Needed)
AI Platform and NoteBooks
- AI Platform is fully managed service for building custom machine learning model.
- Notebooks are de facto standards to develop data analysis and ML jobs. Jupyter notebooks very popular and AI notebooks are basically hosted industry-standard Jupyter Lab. We can configure our environment through GUI and select gpu, tpu.
How AI platform notebooks work?

Kubeflow
- Kubeflow is open source project which is designed to run ML workloads on Kubernetes cluster.
- In simple terms you can build your ML models with Kubeflow pipelines using Kubeflow ML stack & deploy on Kubernetes cluster. Kubernetes cluster will manage scalability and complexity.
- Kubeflow pipelines are portable through packaging that means same pipeline can work across the cloud provider.
- Typical ML Pipeline might contain following phases.


AI Hub
- Repository for ML components. Example would building Kubeflow pipeline, package it and share it via AI Hub repository.
- We can store assets like Jupyter notebooks, Kubeflow pipeline, Tensorflow modules, trained models, VM images.
- Assets can be Public or Private types.
BigQuery ML(No ML Expertise Needed)
- With BiQuery ML we can train our model on structured data using SQL itself.
- General use case scenarios are classification, DNN(deep neural network), gradient descent.
Example of Logistic Regression
model_type = ‘logistic_req’ , this line tells BQ to apply logistic regression model on the data and input label is “on_time”


- We can export the model from TensorFlow to predict in BigQuery.
- We can also build recommendation engine in BigQuery ML.
- We can also run unsupervised Learning (example K-Means clustering) in BigQuery ML
Cloud AutoML (No ML Expertise Needed)
- Cloud AutoML is ML service on GCP which is useful if need to get ML model in production as quickly as possible with minimum effort. We don’t need to have ML expertise .
- With Cloud AutoML we even don’t have to write any code. We just need to training using our data and AutoML will take care of end to end process from processing to algorithm selection and deployment .
Followings are the products in AutoML :
AutoML Vision : Specializes for training ML model for images.
AutoML NLP : Specializes in training ML model for texts.
AutoML Tables : AutoML table is for structured data ( tabular data) , Specializes in training ML models for tabular data.
Comments
Post a Comment